The "Boehm-Demers-Weiser" Conservative Garbage Collector
Outline
- Introduction
- Interface
- Implementation basics & goals
- Implementation details and issues
- Core collector
- Enhancements
- Experiences and a few measurements
概述
- 导言
- 接口
- 实现基础与目标
- 实现细节和问题
- 核心回收器
- 增强功能
- 经验和一些测试
What is it?
- A garbage collecting replacement for C's malloc().
- Calls to free() are optional.
- Unreachable memory is automatically reclaimed, and made available to future malloc() calls.
- A tracing (mark/sweep) garbage collector.
- It periodically determines which objects can be reached by following pointers.
- The rest can be reused for other purposes.
- An easy way to add garbage collection to a runtime system.
- Easy to interface to.
- Interacts well with C/C++ code.
- Gcj (Java), Mono (C#, .NET), Bigloo (Scheme), MzScheme.
- A leak detector for programs that call free().
- Unreachable unfreed memory is a memory leak.
他是什么?
- 一个可以替代
C中malloc()的垃圾回收器。- 对
free()的调用是可选的。 - 不可达内存会自动回收,并提供特性
malloc()用以调用。
- 对
- 一个跟踪(
Marks&Weep)垃圾回收器。- 它定期确定可以通过跟随指针判断哪些对象可达。
- 也可以用于其他目的。
- 一个简单的方法将该垃圾回收加入到运行时系统.
- 易于接口。
- 与
C/C++代码交互良好。 GCJ(Java)、Mono(C#, .NET)、Bigloo(Scheme)、MzScheme。
- 用于调用
free()的程序的泄漏检测器。- 不可达的并且未释放内存是内存泄漏。
GCJ = GNU Compiler for the Java Programing Language(GNU Java语言编译器)
Java源文件 ->Java字节码文件Java源文件 ->Java本地机器码Java字节码文件 ->Java本地机器码
Bigloo: Bigloo是一个高效的Scheme语言编程环境
通过将 Scheme 转成 C 语言来优化编译,Bigloo 允许在 Scheme 和 C 语言间进行连接。
MzScheme: MzScheme是一个高效的Scheme语言编程环境
Example: Lisp S-expressions
#include "gc.h"
typedef union se
{
struct cons * cp;
int i;
} sexpr;
struct cons
{
union se head;
union se tail;
};
#define car(s) (s).cp->head
#define cdr(s) (s).cp->tail
#define from_i(z) ({sexpr tmp; tmp.i=z; tmp;})
#define to_i(s) (s).i
sexpr cons(sexpr a, sexpr b)
{
sexpr tmp = {GC_MALLOC(sizeof(struct cons))};
car(tmp) = a;
cdr(tmp) = b;
return (tmp);
};
int main()
{
return to_i(car(cons(from_i(0), from_i(1))));
}
示例:Lisp S-expressions
替换 malloc() 为 GC_MALLOC()?
Where did it come from?
- Began life (ca. 1980) as a simple GC for the Russell programming language. ( Demers was original author.)
- Later (ca. 1985?) changed to remove restrictions on generated code, and allow
use in the compiler itself.
- Eliminate endless debugging of manual reference counting.
- Used for student compilers for a language with higher-order functions.
- Mark Weiser explored use as leak detector (ca. 1986).
- A variant served as the Xerox Cedar GC from the late 80s, replacing reference-count collector.
- Unrelated to an earlier garbage collector for C written by Doug McIlroy and apparently layered on top of malloc.
它是从哪里来的?
- 作为
Russell编程语言的简单GC开始生活(约 1980 年)。(德默斯是原作者。) - 后来(大约 1985 年?)更改为删除对生成代码的限制,并允许在编译器本身中使用。
- 消除手动引用计数的无休止调试。
- 用于具有高阶函数的语言的学生编译器。
Mark Weiser探索了用作检漏仪的用途(约 1986 年)。- 80 年代后期的
Xerox Cedar GC变体取代了引用计数收集器。 - 与
Doug McIlroy为C编写的早期垃圾收集器无关,并且显然位于malloc之上。
What else can it do?
- 20 years of creeping features, including:
- Invoking finalizers after an object becomes unreachable.
- Support for use in runtime systems.
- If the compiler wants to help, it can.
- Support for heap debugging.
- What's in the heap?
- Why is it still there? How can it still be referenced?
- Support for threads and multiprocessor GC.
- Maybe a way to speed up standard C applications on multiprocessors?
- Various mechanisms for reducing GC pauses:
- Incremental (but not hard real-time) GC.
- Generational GC which concentrates effort on young objects. (But objects are not moved.)
- Abortable collections.
它还能做什么?
- 20年来的缓慢支持,包括:
- 在对象变得不可达后调用终结器。
- 支持在运行时系统中使用。
- 如果编译器也需要帮助,它可以做到。
- 支持 堆 调试。
- 堆 里有什么?
- 为什么它还在那里?它怎么还能被引用?
- 支持线程和多处理器
GC。- 也许是一种能在多处理器上加速标准
C应用程序的新方式?
- 也许是一种能在多处理器上加速标准
- 减少
GC暂停的各种机制:- 增量(但不是硬实时)
GC。 - 将精力集中在年轻对象上的分代
GC.(但是对象并不会移动.) - 可中止回收过程。
- 增量(但不是硬实时)
这里说明了, 该算法并不打算把对象拷贝来拷贝去的.
对于机身性能还没溢出的产品上, 使用该GC算法, 可以说是一个比较好的方案了.
比如手机.
What can't it do?
- Reclaim memory or invoke finalizers/destructors immediately.
- Like all tracing garbage collectors, it only checks for unreachable memory occasionally.
- And synchronous heap finalizers are broken anyway...
- Reclaim all unreachable objects.
- Generally a few will still have pointers to them stored somewhere.
- The GC doesn't know which registers will be referenced.
- And there are other issues ...
- And unreachable isn't well-defined anyway ...
- But we generally avoid growing leaks.
它不能做什么?
- 立即回收内存或调用终结器/析构函数。
- 与所有跟踪垃圾收集器一样,它只是偶尔检查不可达内存.
- 无论如何, 同步堆终结器都被破坏了...
- 回收所有所有不可达对象。
- 一般来说,一些人仍然会在某处存储指向它们的指针。
GC不知道将引用哪些寄存器。- 还有其他问题...
- 不可达其实也是不很明确的定义...
- 但我们通常会避免越来越多的泄漏。
Dealing with C: Conservative Garbage Collection
- For C/C++ programs, we may not know where the pointer variables (roots) are.
- We may want to use a standard compiler. (Slightly risky with optimization, but popular.)
- Program may use C unions.
- Even layout of heap objects may be unknown.
- It's easier to build a Java/Scheme/ML/... compiler if pointer location information is optional.
- Conservative collectors handle pointer location uncertainty:
- If it might be a pointer it's treated as a pointer.
- Objects with ambiguous references are not moved.
- And we never move any objects.
- May lead to accidental retention of garbage objects.
与C打交道:保守的垃圾收集
- 对于
C/C++程序,我们可能不知道指针变量(root set)在哪里。- 我们可能需要使用标准编译器。(优化有点风险,但是很受欢迎。)
- 程序可以使用
C的union(联合)。
- 甚至堆对象的布局也可能是未知的。
- 如果指针位置信息是可选的。那么构建
Java/Scheme/ML...编译器就会更容易. - 保守收集器处理指针位置不确定性:
- 如果它可能是一个指针,则将其视为指针。
- 不移动具有不明确引用的对象。
- 毕竟, 我们从不移动任何物体。
- 可能会导致垃圾对象的意外保留。
引用 高川老师 演讲时候的话,
在保守内存回收器来看,当回收一个内存块的时候,会尝试找到内存块下边所有的指针指向的地址,并且标记为引用。比如说 Object a 引用了 Object b ,当 Object a 不能回收的时候,会同时标记 Object b 也不能被回收。
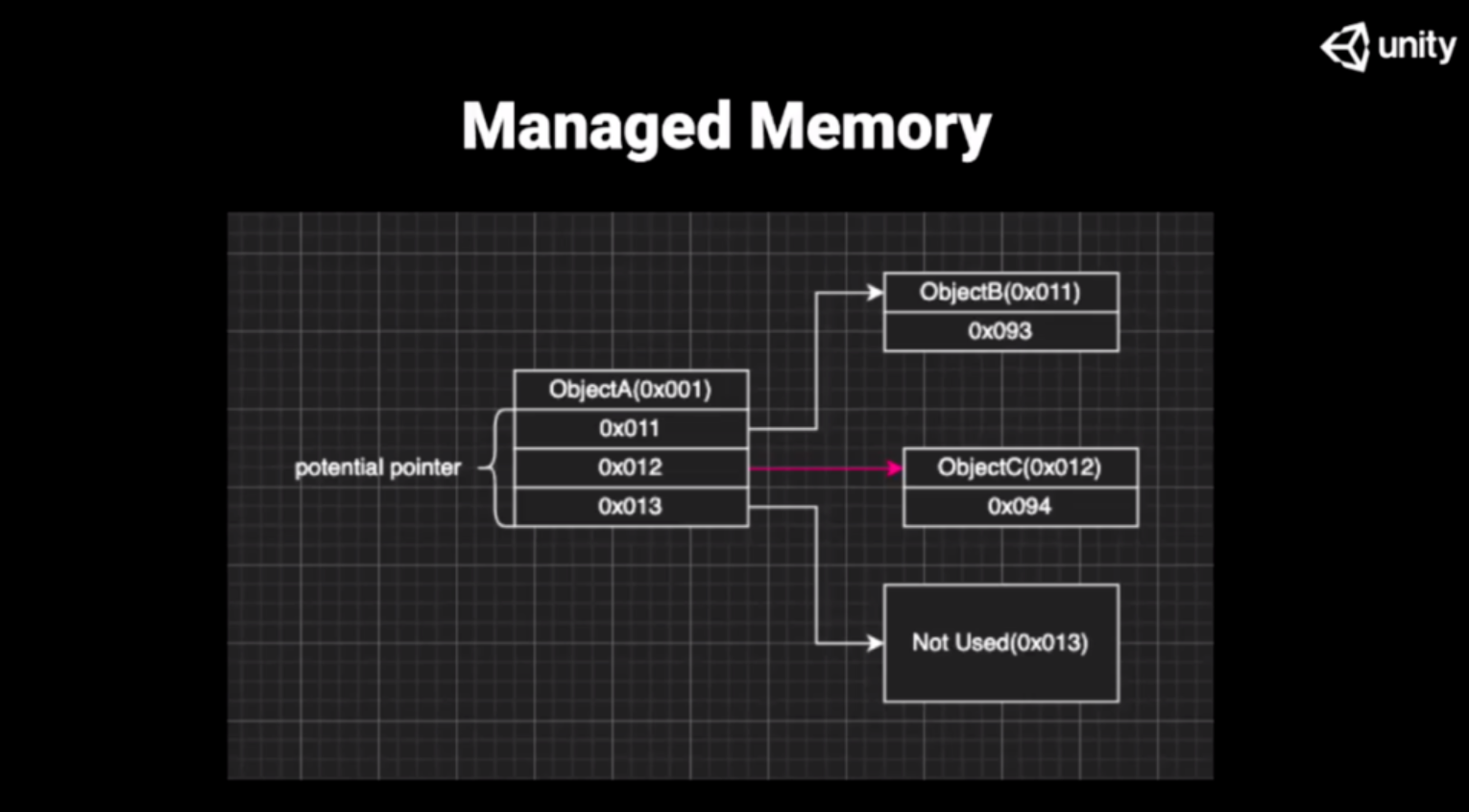
- 如何知道这个东西是一个数还是一个指针的?
- 靠猜!
这有一个 potential pointer潜在指针,并不知道它是不是真的指针,而以一个 pattern 的方式来检查当前这个数有没有可能是一个指针。
比如说第一个指针,检查0x011这个数值所指向的地址里边有没有东西,若有就标记成 1 ,这次不回收。0x012 指向了 Object c, Object c 和 Object a 没有应用依赖关系,但是它恰好分配到了这块内存上。
对于贝母来说,指的这块地方,有东西不回收。0x013 指向了一块没用的内存。
贝母垃圾回收会把这个地址加到黑名单里。当下次进行大内存分配的时候,刚好踩到了这个地址的时候,贝母会告诉你这块内存不能用,贝母把它先留下了,你再去分配一块。
这就是非精准,对于要回收的内存,它可能收不回来,对于没用的内存,它也可能不让用。
C Interface overview
Debugging support: GC_xyz() vs. GC_XYZ() functions:
- GC_xyz() is the real function.
- GC_XYZ(x) expands to either
GC_xyx(x)orGC_debug_xyz(x, <source position, etc>). - Clients should:
- Use the all-caps version.
- Always include gc.h.
- Define GC_DEBUG before including gc.h for debugging.
- This is becoming obsolete technology.
- Requires too much recompilation.
- Libunwind, addr2line allow better alternatives.
C接口概述
调试支持:GC_xyz() vs. GC_XYZ():
GC_xyz()是真正的函数.GC_XYZ(x)展开为GC_xyx(x)orGC_debug_xyz(x, <source position, etc>)- 客户端应该:
- 使用全大写版本。
- 始终包括
gc.h - 在包含
gc.h进行调试之前定义GC_DEBUG。
- 这正在成为过时的技术。
- 需要太多的重新编译。
Libunwind、addr2line允许更好的选择。
C interface, main functions
- GC_MALLOC(bytes)
- In simple cases, this is enough.
- GC_MALLOC_ATOMIC(bytes)
- Allocate pointer-free or untraced (but collected) memory.
- GC_MALLOC_UNCOLLECTABLE(bytes)
- Allocate uncollectable (but traced) memory.
- GC_REALLOC(p, bytes)
- GC_REGISTER_FINALIZER(...)
- Register (or unregister or retrieve) "finalizer" code to be called when an object is otherwise "unreachable".
- Unlike Java, by default, an object is reachable if it can be referenced from other finalizers. (Also Java variant.)
- GC_INIT() Optional on most platforms. (Must be called from main program on a few.)
- GC_FREE() If you insist. (Usually helps performance for large objects, hurts for small ones.)
- GC_MALLOC_IGNORE_OFF_PAGE() Like GC_MALLOC(), but for large arrays with pointers to (near) the beginning.
- Plus statistics, control of incremental GC, more allocator variants, heap limits, GC frequency controls, fast inline allocators, etc.
C 接口, 主要的一些方法:
GC_MALLOC(bytes)- 在简单的情况下,这就足够了。
GC_MALLOC_ATOMIC(bytes)- 分配无指针或未跟踪(但已回收过)内存。
GC_MALLOC_UNCOLLECTABLE(bytes)- 分配无法回收的(但已跟踪)的内存。
GC_REALLOC(p, bytes)GC_REGISTER_FINALIZER(...)- 注册(或注销或检索)"终结器"代码以在对象"不可达"时调用。
- 与
Java不同,默认情况下,如果可以从其他终结器引用对象,则该对象是可访问的。(Java变体也是。)
GC_INIT()- 在大多数平台上都是可选的。 (必须在少数情况下从主程序调用。)
GC_FREE()- 如果你坚持. (通常对大对象有帮助,对小对象有伤害.)
GC_MALLOC_IGNORE_OFF_PAGE()- 与
GC_MALLOC()类似, 但用于指针指向(接近)开头的大型数组。
- 与
- 加上统计数据、增量
GC控制、更多分配器变量、堆限制、GC频率控制、快速内联分配器等。
C++ interface
- "gc_cpp.h" provides a base class gc:
- Overrides new to be GC_MALLOC for subclasses of gc.
- Overrides ::new to be GC_MALLOC_UNCOLLECTABLE.
- Provide gc_cleanup class which registers destructor as finalizer.
- Built by Detlefs, Hull, based on Ellis, Detlefs work.
- ...
- "gc_allocator.h" defines STL allocators:
- gc_allocator
- traceable_allocator
- Particularly gc_cpp.h is annoyingly brittle.
- Perhaps more so than some of the gross hacks we'll hint at later.
- Replacing global operator new seems problematic for many compilers.
C++接口
- "
gc_cpp.h"提供了一个基类gc:- 为
gc的子类覆盖new为GC_MALLOC。 - 将
::new覆盖为GC_MALLOC_UNCOLLECTABLE。 - 提供将析构函数注册为终结器的
gc_cleanup类。 Detlefs由赫尔的Detlefs建造,基于Ellis,Detlefs工作。- ...
- 为
- "
gc_allocator.h"定义STL分配器:gc_allocatortraceable_allocator(可追踪分配器)
- 尤其是
gc_cpp.h非常脆弱。- 也许比我们稍后会暗示的一些严重的黑客攻击更重要。
- 对许多编译器来说,替换全局运算符
new似乎有问题。
Environment variables
- Collector can be influenced by various environment variables:
- GC_INITIAL_HEAP_SIZE
- GC_MAXIMUM_HEAP_SIZE
- GC_PRINT_STATS
- GC_DUMP_REGULARLY
- GC_ENABLE_INCREMENTAL (caution!)
- GC_PAUSE_TIME_TARGET
- GC_DON'T_GC
- GC_IGNORE_GCJ_INFO ignore compiler-provided pointer location information.
- GC_MARKERS Set the number of GC threads (where supported).
- ...
环境变量
- 回收器可能会受到各种环境变量的影响:
GC_INITIAL_HEAP_SIZEGC_MAXIMUM_HEAP_SIZEGC_PRINT_STATSGC_DUMP_REGULARLYGC_ENABLE_INCREMENTAL(小心使用!)GC_PAUSE_TIME_TARGETGC_DON'T_GCGC_IGNORE_GCJ_INFO- 忽略编译器提供的指针位置信息。
GC_MARKERS- 设置
GC线程的数量(如果支持)。
- 设置
- ...
How does it work?
Occasionally (when we run out of memory?):
- Mark all objects referenced directly by pointer variables (roots)
- Repeatedly:
- Mark objects directly reachable from newly marked objects.
- Finally identify unmarked objects (sweep)
- E.g. put them in free lists.
- Reuse to satisfy allocation requests.
- Objects are not moved.
它是如何工作的?
偶尔(当我们用完内存时?):
- 标记指针变量(
roots set)能直接引用到的所有对象 - 重复地:
- 标记可从新标记的对象直接可达的对象。
- 最后识别未标记的对象(清除)
- 例如: 把他们放在
free list上。 - 重用以满足分配内存请求。
- 例如: 把他们放在
- 对象不会移动。
Mark/sweep illustration
第一步(标记):
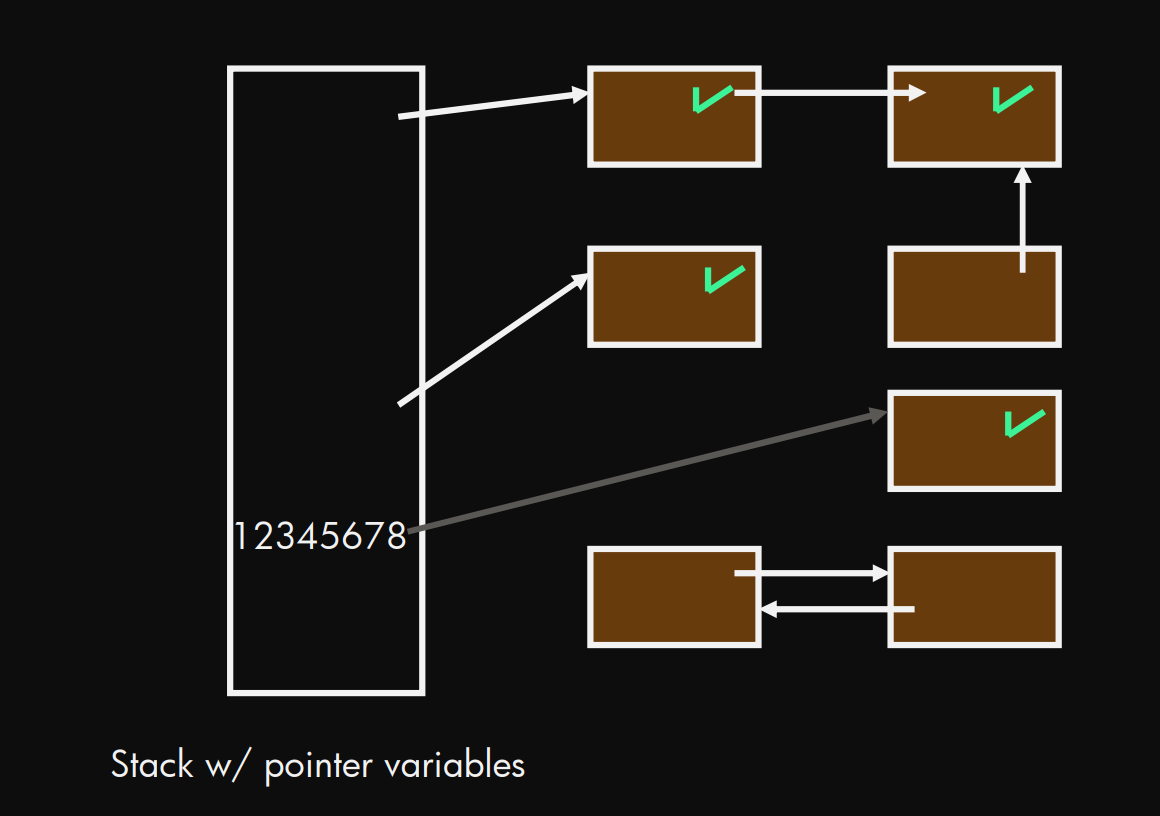
第二部(清除)
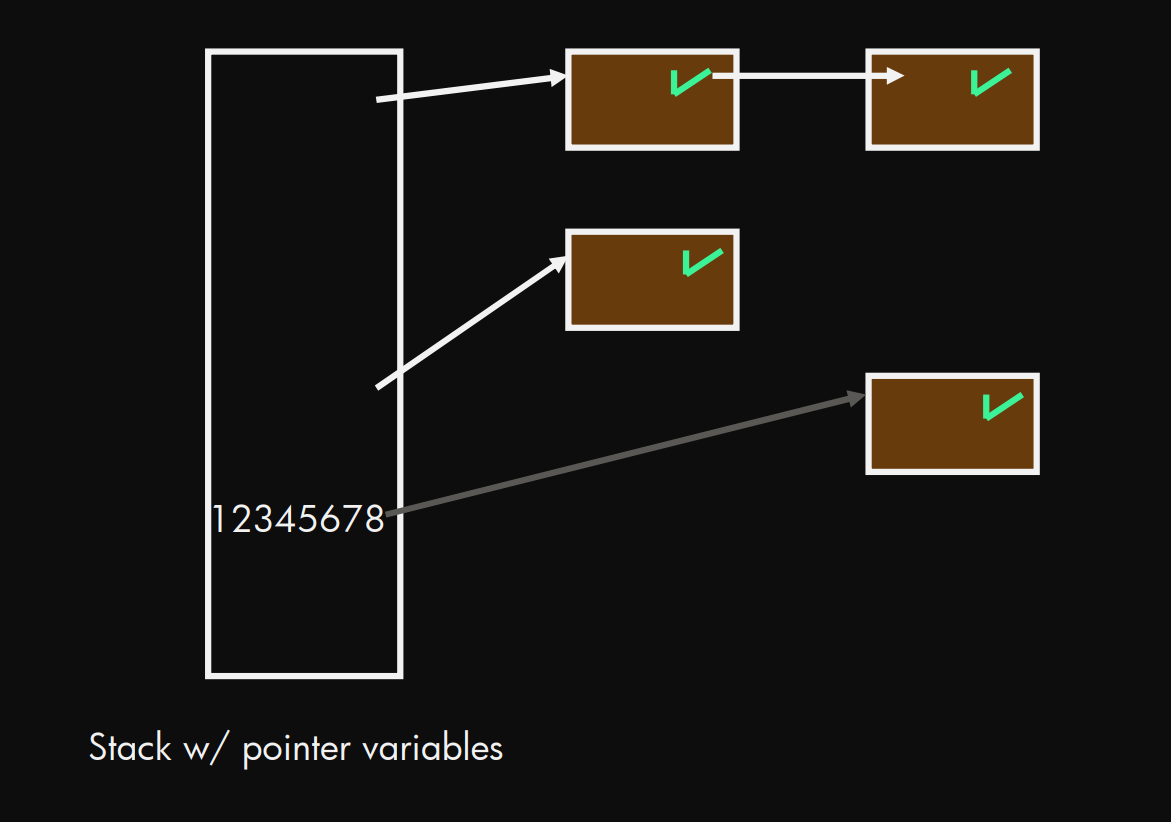
标记/清除 插画
从Stack(根)出发, 依次标记(绿色对勾)标记可达的 堆 的内存空间. 然后"清除"未被标记的.
从图示来理解:
这里这个清除其实蛮简单的, 只是单纯放到一个 free list 里面, 等要有需要的时候被重新分配.
Easy performance issue
- If heap is nearly full, we collect too frequently.
- May collect once per allocation.
- We look at all reachable objects each time -> expensive
- Solution:
- Always make sure that heap is e.g. 1.5 times larger than necessary.
- Each cycle, allocate n/3 bytes, trace 2n/3 bytes.
- Trace 2 bytes per byte allocated.

- Performance is often dominated by memory accesses.
- Each reclaimed object is touched twice per cycle.
- Once during sweep phase.
- Once during allocation.
- Solution:
- Sweep a little bit at a time before allocation.
- Try to keep object in cache.
- "Sweep phase" is a misnomer.
- Imposes constraints on GC data structure.
简单性能问题
- 如果堆快满了,我们就回收地更频繁。
- 每次分配可回收一次。
- 我们每次都会查看所有可达的对象 -> 昂贵
- 解决方案:
- 始终确保 堆 比需要的大1.5倍。
- 每个周期,分配
n/3字节时,跟踪2n/3字节。 - 在分配到的内存空间里跟踪前2个字节。
- 性能通常由内存访问决定。
- 每个回收的对象每个周期被触摸两次。
- 一次在清除阶段。
- 一次在分配过程中。
- 解决方案:
- 分配前一次清除一点。
- 尝试将对象保留在缓存中。
- "清除阶段"用词不当。
- 对
GC数据结构施加约束。
Asymptotic Complexity of MarkSweep vs. Copying
- Conventional view:
- Copying: O(live_data_size)
- M/S:
- Mark: O(live_data_size)
- Sweep: O(heap_size)
- Total: O(heap_size)
- M/S more expensive (if heap_size >> live_data_size)
- Alternate view:
- Sweep doesn't count; part of allocation.
- M/S can avoid touching pointer-free data (strings, bitmaps)
- M/S: O(pointer_containing_data)
- Copying more expensive
- (if pointer_containing_data << live_data_size)
运行时间复杂度 M&S vs Copying分析.
- 传统观点:
Copying:O(live_data_size)M&S:- 标记:
O(live_data_size) - 扫描:
O(heap_size) - 总计:
O(heap_size)
- 标记:
M&S复杂度更高当(heap_size>>live_data_size)
- 另一种观点:
- 清除不算数分配的一部分。
M&S可以避免接触无指针数据(字符串、位图)M&S:O(pointer_containing_data)Copying复杂度更高当- (如果
pointer_containing_data<<live_data_size)
- (如果
Implementation details overview
- General design issues:
- The underlying allocator.
- Pointer validity checks and mark bits.
- Partial pointer location information.
- Locating potential roots.
- Mark algorithm and stack overflow.
- Thread support.
- Enhancements:
- Black-listing of "false pointers"
- Incremental/Concurrent/Generational GC.
- Parallel marking.
- Thread-local allocation.
- Finalization.
- Debug support.

实现细节描述
- 一般设计问题:
- 底层分配器。
- 指针有效性检查并标记位。
- 部分指针位置信息。
- 寻找潜在的根
roots set。 - 标记算法和堆栈溢出。
- 线程支持。
- 增强功能:
- "错误指针"黑名单
- 增量/并发/分代
GC。 - 平行标记。
- 线程本地分配。
- 终结。
- 调试支持。
Allocator design
- Segregate objects by size, pointer contents...
- Each "page" contains objects of a single size.
- Separate free lists for each small object size.
- Large object allocator for pages, large objects.
- Characteristics:
- No per object space overhead (except mark bits)
- Small object fragmentation overhead factor:
- < #size classes = O(log(largest_sz/smallest_sz))
- Asymptotically optimal (Robson 71)
- Fast allocation.
- Partial sweeps are possible.
- Can avoid touching pointer-free pages.
分配器设计
- 按大小、指针内容分隔对象...
- 每个
"page"包含单个大小的对象。 - 每个小对象大小都有单独地
free list。 - 用于
page、大对象的大对象分配器。 - 特点:
- 无每对象空间开销(标记位除外)
- 小对象碎片开销系数:
O(log(largest_sz/smallest_sz))- 渐近最优(
Robson 71)
- 快速分配。
- 部分扫描是可能的。
- 可以避免触摸无指针
page。
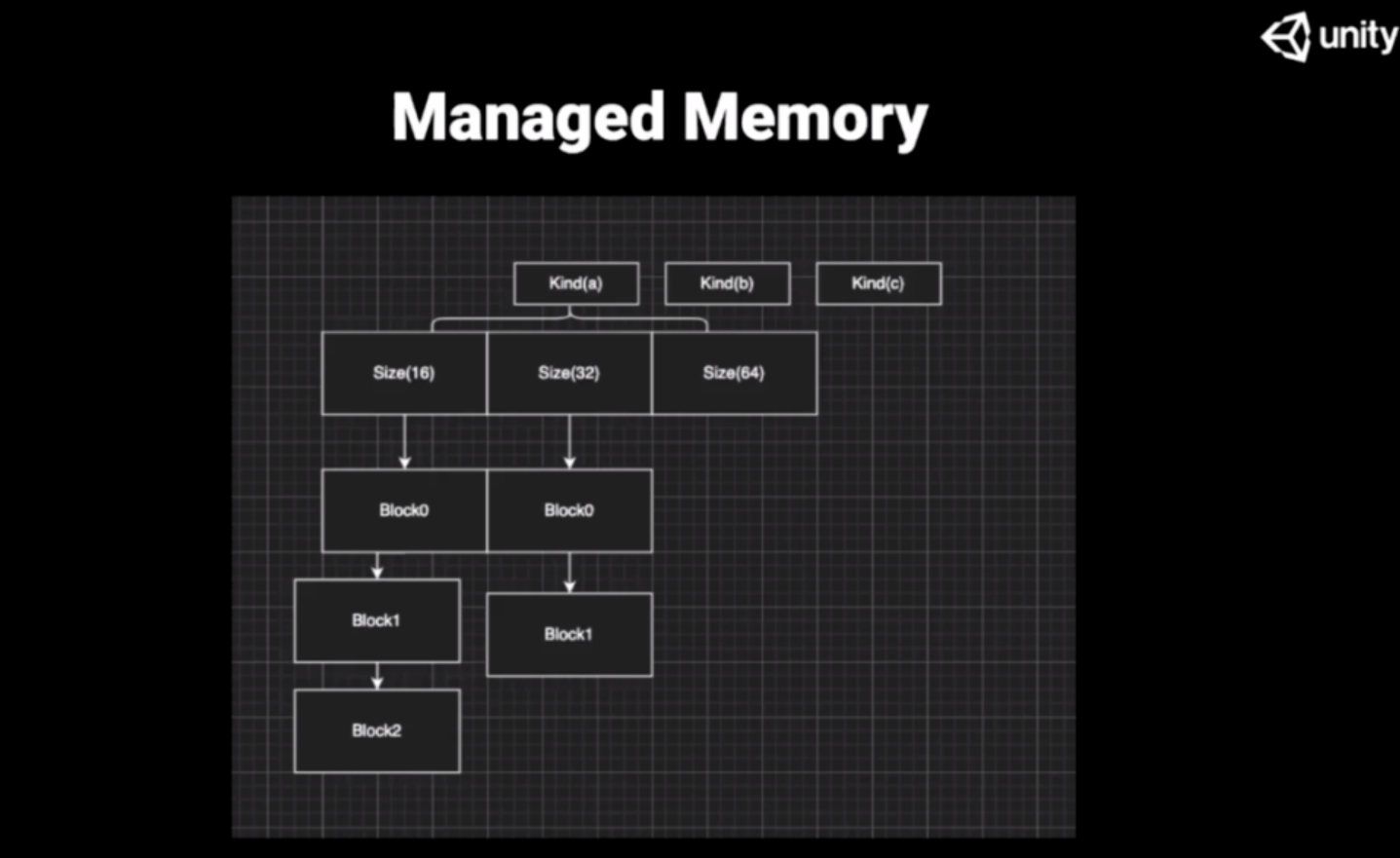
贝母在内存管理的时候,是一个两级的管理:第一级,Kind类型,贝母在分配的时候会分配出很多种不同的类型。
常见的有 PTRFREE(无指针类型),Normal(比较一般的类型),还有 Uncollectable(不可回收类型),一般是贝母自己要用的一块内存会分配到 Uncollectable。
每一个类型是一个列表,在列表下面分别会挂一个二级列表,去标明当前这一块内存块下面的大小,在第二层的下面挂着一个链表,这个链表里边每一块就是对应上面大小的一小块内存。
图中两个 Block0 是物理连接的,这两块物理地址是连续的,假如现在要回收两个 Block0 ,当这两块内存都被释放掉的时候,Unity会尝试去找两块,比如说释放第一块,Unity发现后边的物理内存也是被释放掉的。
便把两块合并起来,让指针直接挂到更大的地方去,从而尽量减少整体内存碎片的发生。这个策略能理解为尽量会把空闲出来的内存合并成一个较大的内存块,同时在以移动指针的方式。
Heap layout
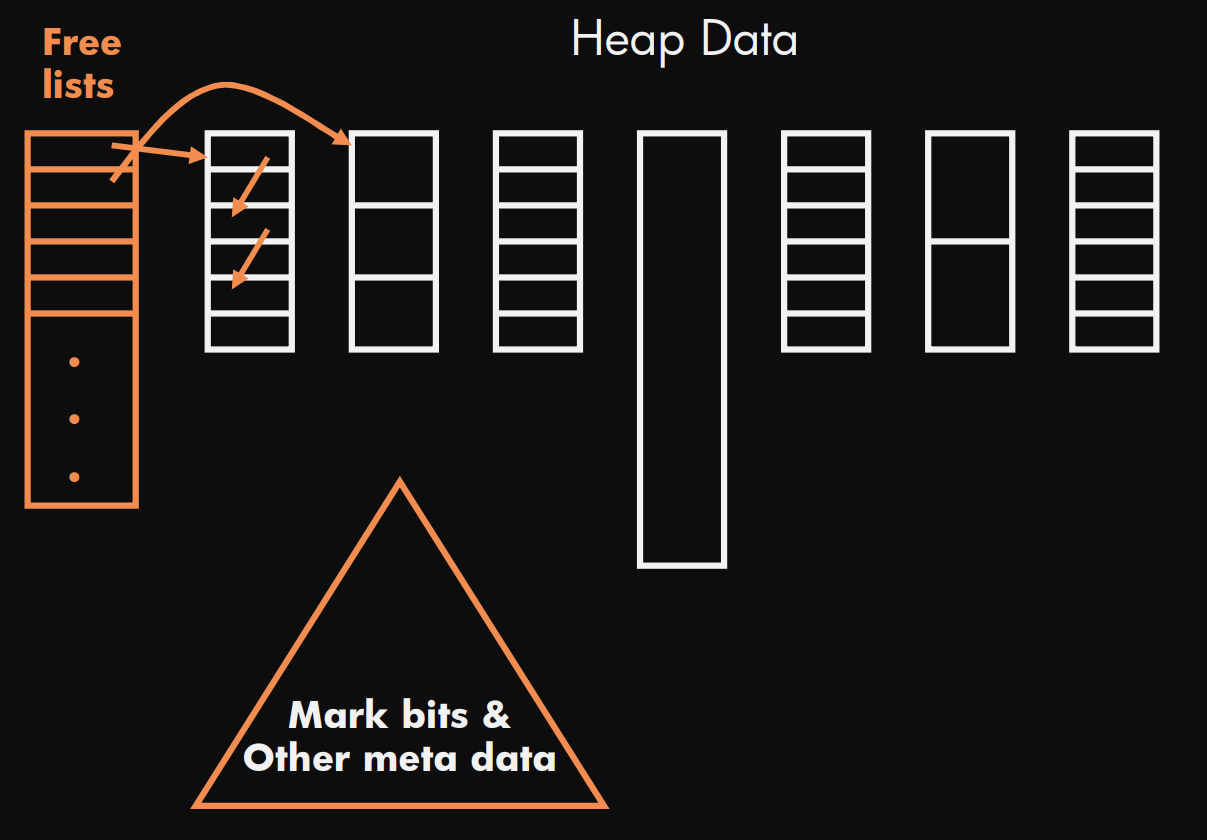
堆布局
Meta-data
- Need mark bit for each object.
- Information for pointer validity & object size, etc.
- Support discontiguous heaps
- Options for mark bits:
- In object:
- Objects: must be aligned.
- Stealing a bit may require a word.
- At beginning of each block:
- All mark bits are mapped to few cache lines.
- Must touch pages with pointer-free objects.
- In separate data structure.
- More instructions for each access.
- Pointer-free pages are not touched, fewer cache issues.
- In object:
元数据
- 每个对象都需要标记位。
- 指针有效性和对象大小等信息。
- 支持不连续堆
- 标记位的选项:
- 在对象中:
- 对象:必须对齐。
- 窃取一个字节可能需要一个单词。
- 在每个块的开头:
- 所有标记位都映射到几个高速缓存行。
- 必须使用无指针对象触摸
page。
- 在单独的数据结构中。
- 每次访问都有更多说明。
- 无指针
page不会被触碰,缓存问题更少。
- 在对象中:
Meta-data lookup
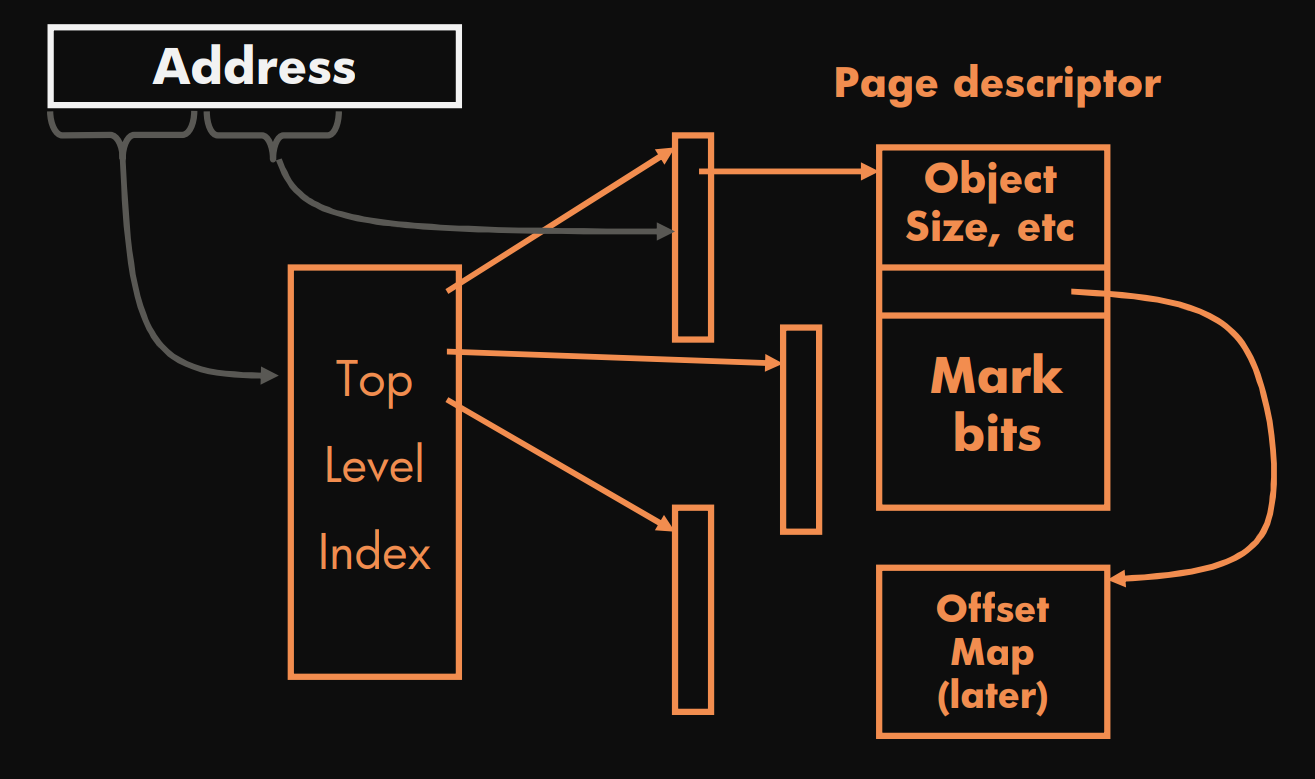
Page descriptor: 页面描述符Mark bits: 标记位Offset Map(later): 偏移表(延迟)
Pointer validity check
- Get page descriptor. Valid heap page?
- About three memory references.
- Simple top level hashing scheme for 64-bit addresses.
- Two with a small cache.
- About three memory references.
- If not first page of object, adjust.
- Valid offset in valid object?
- Remainder computation on offset in page gives object start.
- Remainder can be looked up in table of "valid offsets".
- Allows pointers to only certain offsets in object to be considered valid. Check is constant time.
- Small constant number of memory references.
指针有效性检查
- 获取页面描述符。有效的堆
page?- 大约三次内存引用。
- 64位地址只是一个简单顶层哈希方案。
- 两个带有小缓存。
- 大约三次内存引用。
- 如果不是对象的第一
page,请调整。 - 有效对象中的有效偏移量?
- 页中偏移量的余数计算使对象开始。
- 剩余部分可在"有效偏移"表中查找。
- 只允许指向对象中某些偏移量的指针被视为有效。检查是固定时间。
- 少量恒定数量的内存引用。
Partial pointer location (type) information.
- It's often easy to determine location of pointers in heap objects (e.g. gcj (Java), Mono (.Net)).
- Collector provides different allocation calls to communicate this.
- Objects are segregated both by size and kind.
- Each kind has associated object descriptor:
- First n fields are pointers.
- 30- or 62-bit bitmap identifies pointer locations.
- Client specified mark procedure.
- Indirect: descriptor is in object or vtable.
部分指针位置(类型)信息。
- 确定堆对象中指针的位置通常很容易(例如
GCJ(Java)、Mono(.Net))。 - 回收器提供不同的分配调用来进行通信。
- 对象是按大小和种类分开的。
- 每种类型都有关联的对象描述符:
- 前
n个字段是指针。 - 30位或62位位图标识指针位置。
- 客户指定的标记程序。
- 间接:描述符位于对象或
vtable中。
- 前
Locating roots
- By default roots consist of:
- Registers
- Runtime stack(s)
- Statically allocated data regions
- Main program + dynamic libraries
- How do we get their contents/location?
- Registers: abuse setjmp, __builtin_unwind_init, ...
- Runtime stack(s): you don't really want to know.
- Need consistent caller-save reg. snapshot
- Static data segments: you don't want to know that either.
- Very platform dependent
- But you only have to do it once per platform.
定位根
- 默认情况下,根
roots set包括:- 寄存器
- 运行时栈
- 静态分配的数据区域
- 主程序 + 动态库
- 我们如何得到他们的位置?
- 寄存器:滥用
setjmp__builtin_unwind_init... - 运行时栈:你并不想知道。
- 需要一个固定的调用者来保存
reg.快照
- 需要一个固定的调用者来保存
- 静态数据段:你也不想知道。
- 非常依赖平台
- 但每个平台您只需执行一次。
- 寄存器:滥用
Basic mark algorithm
- Maintain explicit mark stack of pairs:

- Initially:
- For each individual root, push object.
- For each root range, push range.
- Then repeatedly:
- Pop (addr, descr) pair from stack.
- For each possible pointer in memory described by pair:
- Check pointer validity. If valid and unmarked:
- Set mark bit for target. (Already have page descriptor.)
- Push object address and descriptor (from page descriptor)
基本标记算法
- 维护显式标记栈对(
key,value): - 最初:
- 对于每个单独的根(
roots set),推入对象。 - 对于每个根范围,推入整个根范围。
- 对于每个单独的根(
- 然后反复说:
- 从栈中弹出(
addr,descr)对。 - 对于由
pair描述的内存中每个可能的指针:- 检查指针的有效性。如果有效且未标记:
- 为目标设置标记位。(已经有页面描述符。)
- 推入对象地址和描述符(从页面描述符)
- 从栈中弹出(
Marker refinements
- Tune as much as possible.
- This is where the GC spends its time.
- It's the memory accesses that matter.
- Prefetch object as we push its descriptor on stack.
- May save 1/3 of mark time.
- Range check possible pointers for plausibility first.
- Eliminates almost all non-pointers.
- Minor benefit from keeping cache of recently looked up block descriptors.
- Probably more important for 64 bit platforms.
- But uncached lookup is already fast.
标记改进
- 尽量调。
- 这是
GC花费时间的地方。
- 这是
- 重要的是内存访问。
- 当我们将其描述符压入堆时预取对象。
- 可以节省 1/3 个标记时间。
- 范围首先检查可能的指针的合理性。
- 消除了几乎所有的非指针。
- 保留最近查找的块描述符的缓存带来的小好处。
- 对于64位平台可能更重要。
- 但无缓存查找已经很快了。
The marker core (version pre-7.0)
- Retrieve mark descriptor from stack.
- (Possibly retrieve "indirect" descriptor from object.)
- Look for pointers in object satisfying range check. Immediately prefetch at that address.
- For each likely nested pointer, processing first one last:
- Look up header in cache (2 memory references).
- Get offset from beginning of block.
- Divide by object size to get object start, and displacement in object.
- If displacement is nonzero, check table for validity.
- Check mark bit in header.
- If not set, set it, get descriptor from block header, push entry on mark stack.
标记器核心(7.0之前的版本)
- 从栈中检索标记描述符。
- (可能从对象中检索"间接"描述符。)
- 在满足范围检查的对象中寻找指针。立即预取该地址。
- 对于每个可能的嵌套指针,最后处理第一个:
- 在缓存中查找标头(2个内存引用)。
- 从块的开头获得偏移量。
- 除以对象大小以获得对象开始和对象中的位移。
- 如果位移不为零,检查表的有效性。
- 检查头部的标记位。
- 如果未设置,则设置它,从块头获取描述符,将条目推入标记栈上。
这里很大一个篇幅在描写栈. 但描述的是标记器
以下是分配器的相关描述, 合并参考:
栈分配器有三个特点:
- 第一个是特别地快,
- 第二个是特别地小,
- 第三个是临时,
分配器大部分情况下是用来分配临时变量。
当要去分配一块内存的时候,实际上 Unity 帮忙分配了两块内存。
- 第一块是
header,记录了当前这一次分配的一些信息。比如:某一块当前是不是要被删掉,是不是还在用;真正给用户的区域大小;比如说当前块的前面一块是谁。 Header下面才是第二块,即用户的分配使用区域。这一整块内存是在一开始就已经预先分配好的,在进行栈分配的时候,只是在不停的调整栈顶指针,依次向下分配,每一次只在栈的顶端,也就是这块内存的尾部再去分配。
当整个预先分配栈内存被消耗干净了之后,还会额外的拓展出一块新的,这个拓展不是无限的而是有一个大小的限制。
在回收内存时,首先把这块内存的 deleted 的在 Header 里边标记成1,表示这一块内存已经无用了,再栈顶指针回弹就可以了,这样是非常快的。分配和回收一样都是挪栈指针,所以分配和回收都非常地快。
如果回收的位置是中间而不是内存块的尾巴,只需要把头的这个 deleted 的标记成1,也就是标记上已经删除了,直到尾巴被回收,在栈顶指针回弹的时候,会去再检查当前这一块是不是也被删除了,
如果是,栈顶指针再次向上移动,直到找到一个没有被删除的块,或者是挪到了 Header,这样就导致如果尾巴处的内存一直没有释放,中间已经释放的内存块无法再次使用,这就是栈分配器的一个限制,它无法快速立刻去重用已经释放的内存,它必须要等栈顶被释放的时候,才能向回去寻找这些连续内存。
当因为你的数据量太大,把拥挤的临时堆栈撑爆了,有两种方法解决:
- 去减少你们每一帧的数据量。
- 通过Unity源码,把堆栈加大一点。
Marker performance: Why GC needs a fast multiplier.
- On toy benchmark, small objects., 1x1.4GHz Itanium
- 500MB/sec (Peak mem. Bandwidth 6.4GB/sec.)
- About 90 cycles/object. (L3 cache miss ~200cycles)
- About 260MB/sec, 180 cycles/object on a 2GHz Xeon.
- Cache misses matter a lot.
- Divisions are a problem.
- Can easily multiply by reciprocal.
- Integer multiply has around 15 cycles latency on IA64.
- Similar on Pentium 4?
- Very hard to hide latency.
- Table lookup of remainder, mark bit per allocation granule (not object) wins (~20% on P4 Xeon).
- Could we do multiple header lookups & divisions at once to hide latency? Maybe
标记器性能:为什么 GC 需要快速乘法器
- 在玩具基准测试中,小对象,
1x1.4GHz安腾500MB/s(峰值内存。带宽6.4GB/s。)- 大约 90 个周期/对象。(
L3缓存未命中~200cycles)
- 在
2GHz Xeon上大约260MB/s,180 个周期/对象。 - 缓存未命中很重要。
- 分工是个问题。
- 可以很容易地乘以倒数。
- 整数乘法在
IA64上有大约 15 个周期的延迟。Pentium 4类似吗?
- 很难隐藏延迟。
- 余数的表查找,每个分配颗粒(非对象)的标记位获胜(在
P4 Xeon上约为 20%)。
- 我们可以一次进行多个标头查找和划分以隐藏延迟吗?也许
What if the mark stack overflows?
- Likely as you approach memory limit.
- Programmers expect to be able to recover from running out-of-memory
- ... although it is almost never 100% reliable, GC or not.
- We
- Drop part of stack.
- Set overflowed flag.
- If flag is set at end of mark phase:
- Rescan heap. Look for marked -> unmarked pointers.
- Mark again from such targets.
- Repeat if necessary.
- Grow mark stack if possible.
- Never push large number of entries without setting a mark bit.
- Ensures forward progress.
如果标记堆栈溢出
- 可能当您接近内存限制时。
- 程序员希望能够从内存不足中恢复
- ……尽管它几乎从来都不是 100% 可靠的,不管
GC与否。
- ……尽管它几乎从来都不是 100% 可靠的,不管
- 我们
- 删除堆栈的一部分。
- 设置溢出标志。
- 如果在标记阶段结束时设置了标志:
- 重新扫描堆。寻找标记 -> 未标记的指针。
- 从这些目标再次标记。
- 必要时重复。
- 如果可能,增加标记堆栈。
- 切勿在未设置标记位的情况下推送大量条目。
- 确保前进。
The "sweep phase"
- Sweep large objects and completely empty pages eagerly.
- Completely empty pages are easily detectable and surprisingly common.
- Effectively coalesces some small objects very cheaply.
- Sweep small object pages when we encounter an empty free list.
- Separate pages can be swept in parallel.
- Empirically, execution time is almost always dominated by marker.
清除阶段
- 急切地扫描大对象和完全清空页面。
- 完全空白的页面很容易被检测到并且非常普遍。
- 非常便宜地有效地合并一些小对象。
- 当我们遇到一个空的空闲列表时,扫描小对象页面。
- 可以并行扫描单独的页面。
- 根据经验,执行时间几乎总是由标记支配。
Thread support
- Uncontrolled concurrent mutation of data structures can cause objects to be overlooked by marker:

- Results in reclaimed reachable objects.
- We stop threads during critical GC phases.
- Unlike most GCs, threads can be stopped anywhere.
- On most platforms, we send each thread a signal, with handshake in handler.
- Ensures that thread is stopped.
- Pushes register contents onto the (GC-visible) stack.
- Typically requires that thread creation calls be intercepted by GC.
- GC substitutes its own thread start routine.
- Keeps track of threads, shadowing thread library.
线程支持
- 数据结构的不受控制的并发突变会导致对象被标记忽略:
- 导致回收的可达对象
- 我们在关键的
GC阶段停止线程。- 与大多数
GC不同,线程可以在任何地方停止。
- 与大多数
- 在大多数平台上,我们向每个线程发送一个信号,并在处理程序中进行握手。
- 确保线程停止。
- 将寄存器内容推送到(
GC可见的)堆栈上。
- 通常要求
GC拦截线程创建调用。GC替换它自己的线程启动例程。- 跟踪线程,隐藏线程库。
Enhancement 1: Black-listing
- Conservative pointer-finding can cause memory retention:

- In many cases, this is avoidable.
- If we see an address near future heap growth:

- Don't allocate at location 0x1a34c.
- We track pages with bogus pointers to them.
- Marker updates list.
- Allocate at most small pointer-free objects there.
- If we see an address near future heap growth:
- 保守的指针查找会导致内存保留:
- 在许多情况下,这是可以避免的。
- 如果我们在不久的将来看到一个地址堆增长:
- 不要在位置
0x1a34c分配。 - 我们跟踪带有虚假指针的页面。
- 标记更新列表。
- 在那里分配最多小的无指针对象。
- 如果我们在不久的将来看到一个地址堆增长:
Black-listing (contd.)
- Can be substantial improvement, especially with large root sets containing random, but static data.
- Only dynamic data can cause retention.
- But dynamically created data is also more likely to disappear later.
- Usually we see good results with conservative pointer finding, minimal layout information and
- 32 bit address space, heaps up to a few 100MB, or
- 64-bit address space.
黑名单 (续)
- 可以大幅改进,尤其是对于包含随机但静态数据的大型根集。
- 只有动态数据会导致保留。
- 但是动态创建的数据也更有可能在以后消失。
- 通常我们会通过保守的指针查找、最少的布局信息和
- 32 位地址空间,最多可堆到
100MB,或 - 64 位地址空间。
- 32 位地址空间,最多可堆到
Optional enhancements
- Remaining enhancements are (or were) implemented and available, but not all combinable.
可选增强功能
- 剩余的增强功能已(或曾经)实施并可用,但并非全部可组合。
Generational, Incremental, Mostly Concurrent GC
- Observation:
- Running marker concurrently establishes invariant:
- Pointers from marked objects or roots either
- point to marked objects, or
- were modified since object was marked.
- Pointers from marked objects or roots either
- Such a concurrent mark phase can be fixed if we can
- Identify possibly modified objects (and roots)
- Mark again from modified objects.
- Most generational collectors track modifications with a compiler introduced "write barrier".
- We use the VM system, e.g.
- Write protect pages (e.g. mprotect for Linux)
- Catch protection faults (e.g. SIGSEGV)
- Free if allocation is rare, but otherwise not ideal.
- Running marker concurrently establishes invariant:
- Mostly concurrent GC:
- Run concurrent marker once.
- Run fixup marker zero or more times concurrently, preserving invariant, reducing # dirty objects.
- Run fixup marker with threads stopped once.
- Works, reduces pause times, used in other systems.
- Scheduling tricky, requires threads.
- Incremental GC:
- Do a little "concurrent" marking during some allocations.
- Amount of marking proportional to allocation.
- Same pause time benefit, no throughput benefit.
- Generational GC:
- Leave mark bits set after "full GC", but track dirty pages.
- "Fixup GC" is minor GC.
分代、增量、大部分并发
- 观察:
- 运行标记同时建立不变量:
- 来自标记对象或根的指针
- 指向标记的对象,或
- 自标记对象以来已修改。
- 来自标记对象或根的指针
- 如果可以的话,可以修复这样的并发标记阶段
- 识别可能修改的对象(和根)
- 从修改的对象再次标记。
- 大多数世代收集器使用引入“写屏障”的编译器来跟踪修改。
- 我们使用VM系统,例如
- 写保护页面(例如
Linux的mprotect) - 捕获保护故障(例如
SIGSEGV)
- 写保护页面(例如
- 如果分配很少,则免费,否则不理想。
- 运行标记同时建立不变量:
- 主要是并发
GC:- 运行并发标记一次。
- 同时运行修正标记零次或多次,保持不变,减少#脏对象。
- 在线程停止一次的情况下运行修复标记。
- 工作,减少暂停时间,用于其他系统。
- 调度棘手,需要线程。
- 增量
GC:- 在某些分配期间做一些“并发”标记。
- 标记量与分配成正比。
- 相同的暂停时间优势,没有吞吐量优势。
- 分代
GC:- 在
“full GC”之后设置标记位,但跟踪脏页。 “Fixup GC”是次要GC。
- 在
Parallel marking & processor scalability
- As client parallelism increases, eventually we spend all time in sequential part of GC.
- Sweeping is done a page at a time & can be parallelized. What about marking?
- Marking is also quite parallelizable.
- First, and most thoroughly, done by Endo, Taura, and Yonezawa (SC97, 64 processor machine).
- Our distribution contains simpler version ...
并行标记和处理器
- 随着客户端并行度的增加,最终我们将所有时间都花在了
GC的顺序部分。 - 扫描一次完成一页并且可以并行化。标记呢?
- 标记也是相当可并行的。
- 首先,也是最彻底的,由
Endo、Taura和Yonezawa(SC97、64 processor machine)完成。 - 我们的发行版包含更简单的版本...
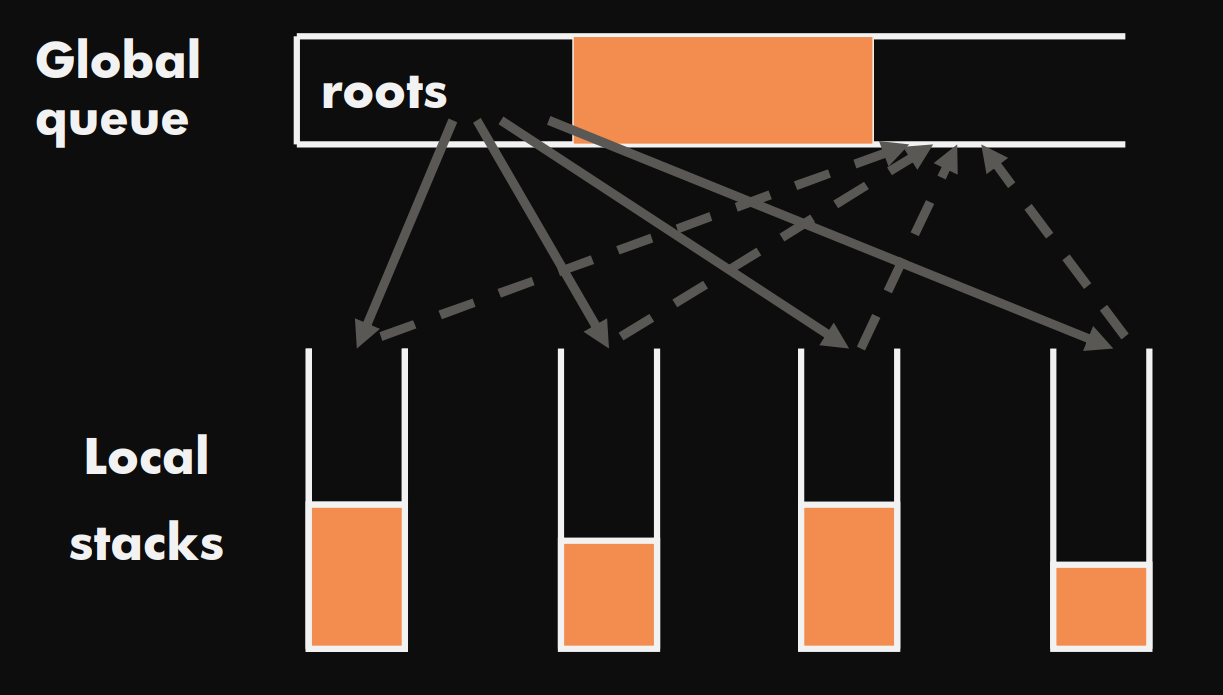
Parallel marking
- For n processors, we have n-1 threads waiting to help with next GC.
- Global mark stack becomes queue.
- Each marker thread regularly:
- Removes a few entries from queue tail.
- Marks from those using a local mark stack.
- Mark bits are shared between marker threads.
- Either use mark bytes, or atomic-compare-and-swap.
- Mark bytes usually win. (1/8 - 1/16 memory overhead.)
- Work may be duplicated but rarely is.
- Either use mark bytes, or atomic-compare-and-swap.
- Load balance by returning part of local stack to top of queue
- When local mark stack overflows.
- When it notices empty global queue.
- Seems to scale adequately, at least for small SMPs.
- Limit appears to be bus bandwidth.
并行标记
- 对于
n个处理器,我们有n-1个线程等待帮助下一次GC。 - 全局标记栈变成队列。
- 每个标记线程定期:
- 从队列尾部删除一些条目。
- 使用本地标记堆栈的标记。
- 标记位在标记线程之间共享。
- 要么使用标记字节,要么使用原子比较和交换。
- 标记字节通常会获胜。(1/8 - 1/16 内存开销。)
- 工作可能会重复,但很少会重复。
- 要么使用标记字节,要么使用原子比较和交换。
- 通过将部分本地堆栈返回到队列顶部来进行负载平衡
- 当本地标记堆栈溢出时。
- 当它注意到空的全局队列时。
- 似乎可以充分扩展,至少对于小型
SMP而言。- 限制似乎是总线带宽。
Parallel marking data structure
Thread-local allocation buffers
- Malloc/free implementations acquire and release a lock twice per object
allocation/deallocation:
- Once per allocation.
- Once per deallocation.
- Garbage collectors avoid per-deallocation lock.
- We can also avoid per-allocation lock!
- Use per-thread allocation caches.
- Each thread allocates a "bunch" of memory.
- Single lock acquisition.
- Dividing it up doesn't require a lock.
- Easy with linear allocation, but also possible here.
- Each thread allocates a "bunch" of memory.
线程局部分配
- Malloc/free 实现每次对象分配/释放两次获取和释放锁:
- 每次分配一次。
- 每次释放一次。
- 垃圾收集器避免每次释放锁。
- 我们还可以避免按分配锁!
- 使用每线程分配缓存。
- 每个线程分配一个“一堆”内存。
- 单锁获取。
- 分割它不需要锁。
- 线性分配很容易,但在这里也是可能的。
- 每个线程分配一个“一堆”内存。
Thread-local allocation details
- Each thread has array of small object free-list headers.
- Each header contains either:
- Count of allocated objects of that size.
- Pointer to local free list.
- To allocate:
- For small counts, increment count, allocate from global free list.
- For count at threshold, or empty free-list, get a page of objects.
- For nonempty free-list, allocate from local free-list.
线程局部分配细节
- 每个线程都有一组小对象空闲列表头。
- 每个标头都包含:
- 该大小的已分配对象的计数。
- 指向本地空闲列表的指针。
- 分配:
- 对于小计数,增加计数,从全局空闲列表中分配。
- 对于阈值计数或空空闲列表,获取对象页面。
- 对于非空空闲列表,从本地空闲列表中分配。
Finalization
- Finalizable objects are added to a growable hash table.
- After each GC, we walk this hash table two or three times:
- Mark all objects reachable from objects in the table.
- But not the objects in the table themselves.
- Table entries contain the procedures to do this marking to handle variants like Java.
- Enqueue still unmarked objects in the table for finalization, and possibly mark them.
- Possibly mark objects reachable from finalizable objects. (Java style finalization only.)
- Mark all objects reachable from objects in the table.
- Process finalizable objects, preferably in separate thread, once allocation lock is released. (See POPL 2003 paper.)
- Weak pointers ("disappearing links") are handled similarly.
终结
- 可终结对象被添加到可增长的哈希表中。
- 每次
GC之后,我们会遍历这个哈希表两到三遍:- 标记从表中的对象可到达的所有对象。
- 但不是表中的对象本身。
- 表条目包含执行此标记以处理
Java等变体的过程。
- 将表中仍未标记的对象排入队列以进行最终确定,并可能标记它们。
- 可能标记可从可终结对象到达的对象。(仅限
Java风格的最终确定。)
- 标记从表中的对象可到达的所有对象。
- 一旦分配锁被释放,最好在单独的线程中处理可终结的对象。(参见
POPL 2003论文。) - 弱指针(“消失的链接”)的处理方式类似。
Finalization (quick observations)
- Finalization is moderately expensive.
- Extra space overhead.
- Tracing cost is significantly higher, even with Java-style finalization (factor of 5?)
- Clients should avoid registering unnecessary finalizers. (JVMs can do this statically.)
- Finalizers do not affect performance of the rest of the GC.
- Finalizers must introduce concurrency (even if we had a simple reference
counting collector). There is no such thing as deterministic finalization for
heap objects.
- Collector runs them in GC_malloc by default. This is a bug except in very simple cases. Use GC_finalizer_notifier.
- Concurrency is tricky. Be careful.
终结(快速观察)
- 最终确定的成本适中。
- 额外的空间开销。
- 跟踪成本明显更高,即使使用
Java风格的终结(5 倍?)
- 客户端应避免注册不必要的终结器。(
JVM可以静态地执行此操作。) - 终结器不会影响
GC其余部分的性能。 - 终结器必须引入并发性(即使我们有一个简单的引用计数收集器)。堆对象没有确定性终结之类的东西。
- 收集器默认在
GC_malloc中运行它们。除了非常简单的情况外,这是一个错误。使用GC_finalizer_notifier。 - 并发是棘手的。当心。
- 收集器默认在
Debugging support
Debug allocators "wrap" each object with extra information:
- Source file, line number of allocation site.
- Possibly a stack trace for allocation site.
- Space for a back pointer. (Should be elsewhere...)
- Requested object size.
- Magic (address dependent) numbers before and after object.
Can mostly tolerate a mixture of wrapped and unwrapped objects.
- Relies on "magic numbers".
- May lead to extra error reports.
调试分配器用额外的信息“包装”每个对象:
- 源文件,分配站点的行号。
- 可能是分配站点的堆栈跟踪。
- 后向指针的空间。(应该在别处……)
- 请求的对象大小。
- 对象前后的魔术(地址相关)数字。
大多数情况下可以容忍包裹和未包裹物体的混合。
- 依靠“幻数”。
- 可能导致额外的错误报告。
Debugging facilities
- GC can check for overwrite errors.
- Various error checks in GC_debug routines.
- Can be configured for leak detection.
- Can tell you whether a single misidentified pointer might result in unbounded space leak (See POPL 2002)
- Can give back-traces of random heap samples (requires different build flags):
****Chose address 0x81ac567 in object 0x81ac568 (trace_test.c:13, sz=8,
PTRFREE)
Reachable via 0 levels of pointers from offset 4 in object:
0x8192090 (trace_test.c:11, sz=8, NORMAL)
Reachable via 1 levels of pointers from offset 0 in object:
0x81920b8 (trace_test.c:11, sz=8, NORMAL)
Reachable via 2 levels of pointers from root at 0x8055bd4
调试设施
GC可以检查覆盖错误。GC_debug例程中的各种错误检查。- 可配置用于泄漏检测。
- 可以告诉您单个错误识别的指针是否可能导致无限空间泄漏(参见
POPL 2002) - 可以提供随机堆样本的回溯(需要不同的构建标志):
Current state
- Easily available (google "garbage collector")
- Supports Linux, Unix variants, Windows, MacOSX,
- Used in a variety of C/C++ systems
- w3m, vesta, ...
- High end Xerox printers.
- Sometimes as leak detector (e.g Mozilla).
- Usually with little type information.
- Used in many language runtimes:
- Gcj (gcc), Mono, Bigloo Scheme
- Usually with heap type information.
- Information on static data (e.g. 4.5MB for gcj) would be easy and useful.
- Current version 6.3; 6.4 should appear shortly.
- Stay tuned for 7.0alpha1 (cleaner code base, ...)
- 容易获得(百度一下“垃圾收集器”)
- 支持
Linux、Unix变体、Windows、MacOSX、 - 用于各种
C/C++系统w3m,vesta, ...- 高端施乐打印机。
- 有时用作检漏仪(例如
Mozilla)。 - 通常只有很少的类型信息。
- 在许多语言运行时中使用:
Gcj (gcc)、Mono、Bigloo方案- 通常带有堆类型信息。
- 有关静态数据的信息(例如,
gcj为4.5MB)将是简单而有用的。
- 当前版本
6.3;6.4应该很快就会出现。 - 请继续关注
7.0alpha1(更简洁的代码库,...)
Performance characteristics
- We use GCBench here.
- More of a sanity check than a benchmark.
- Allocates complete binary trees of varying depths.
- Depth n -> 2 n - 1 nodes of 2 pointers + 2 ints
- Translated to multiple source languages.
- Can see effect of object lifetime.
- About as realistic as any toy benchmark (not very)
性能特点
- 我们在这里使用
GCBench。- 与其说是基准,不如说是健全性检查。
- 分配不同深度的完整二叉树。
- 深度 n -> 2 n - 2 个指针的 1 个节点 + 2 个整数
- 翻译成多种源语言。
- 可以看到对象生命周期的影响。
- 与任何玩具基准一样逼真(不是非常)
GCBench vs HotSpot 1.4.2 client
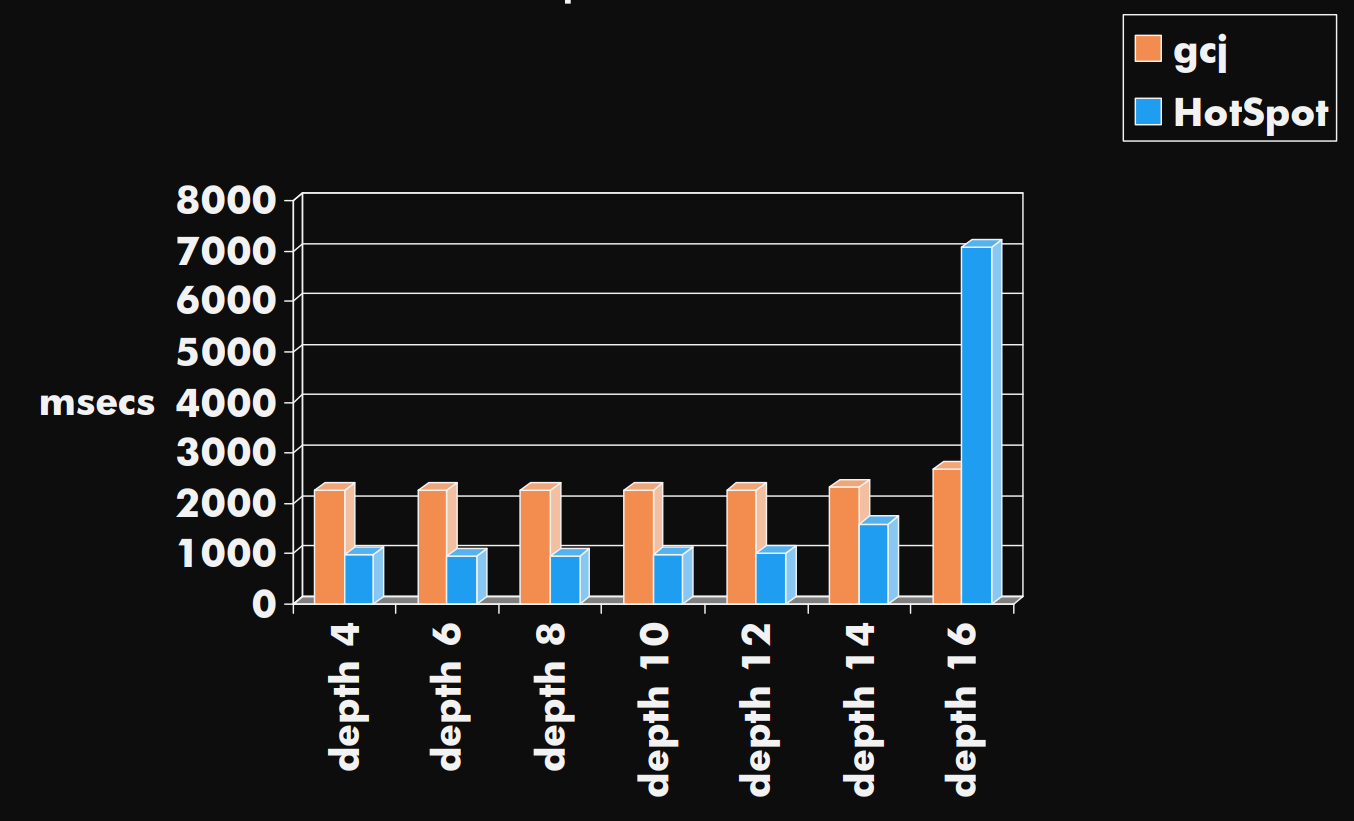
C/C++ GCBench Comparison
- Compare:
- C with malloc/free
- "Pause" is tree deallocation time (predictable).
- Boost classic reference counting (simple and tuned version)
- "Pause" is recursive deallocation time during assignment(unpredictable).
- Boost versions use C++ benchmark.
- Expl. free and BDW GC use C version.
- HotSpot uses Java version.
- C with malloc/free
C/C++ GCBench 比较
- 比较:
C带malloc/free- “暂停”是树释放时间(可预测)。
- 提升经典引用计数(简单和调整的版本)
- “暂停”是分配期间的递归释放时间(不可预测)。
Boost版本使用C++基准测试。- 解释。
free和BDW GC使用C版本。 HotSpot使用Java版本。
Execution time (msecs, 2GHz Xeon) vs. alternatives
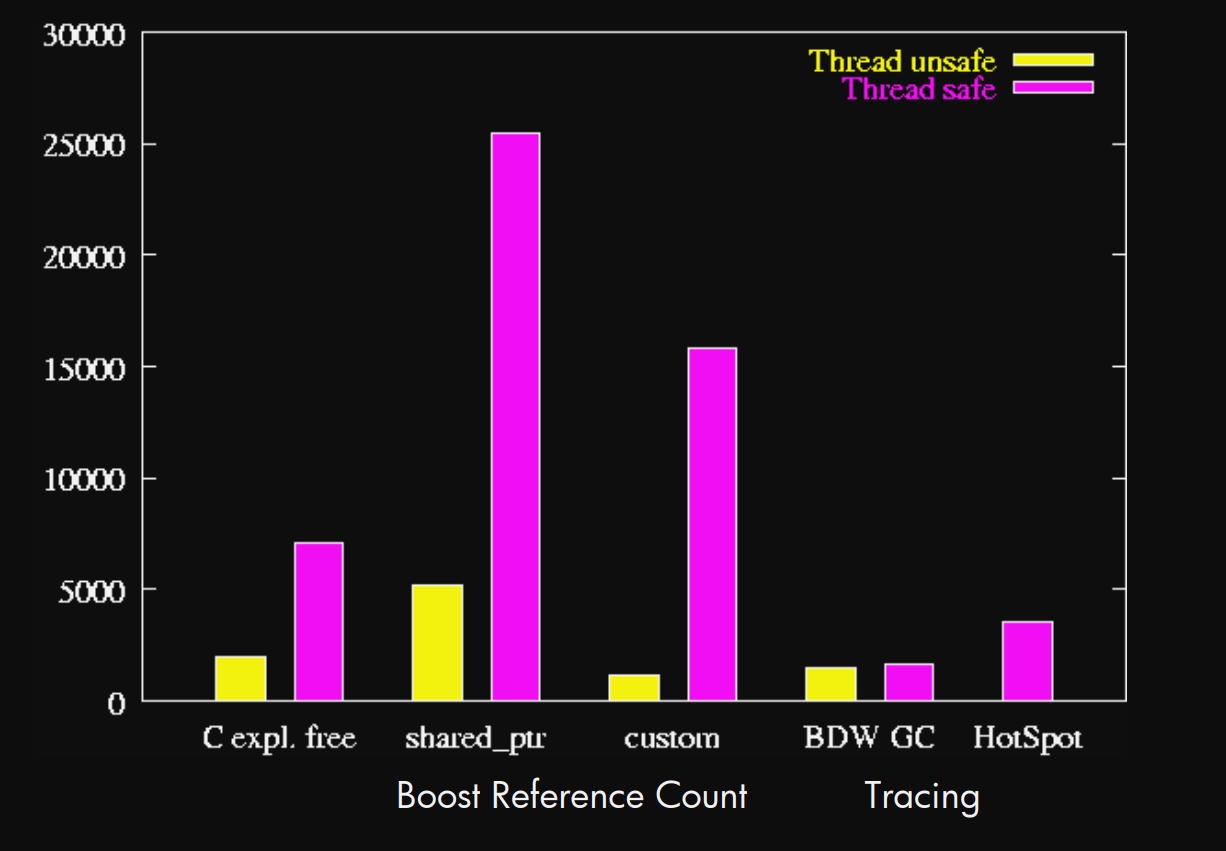
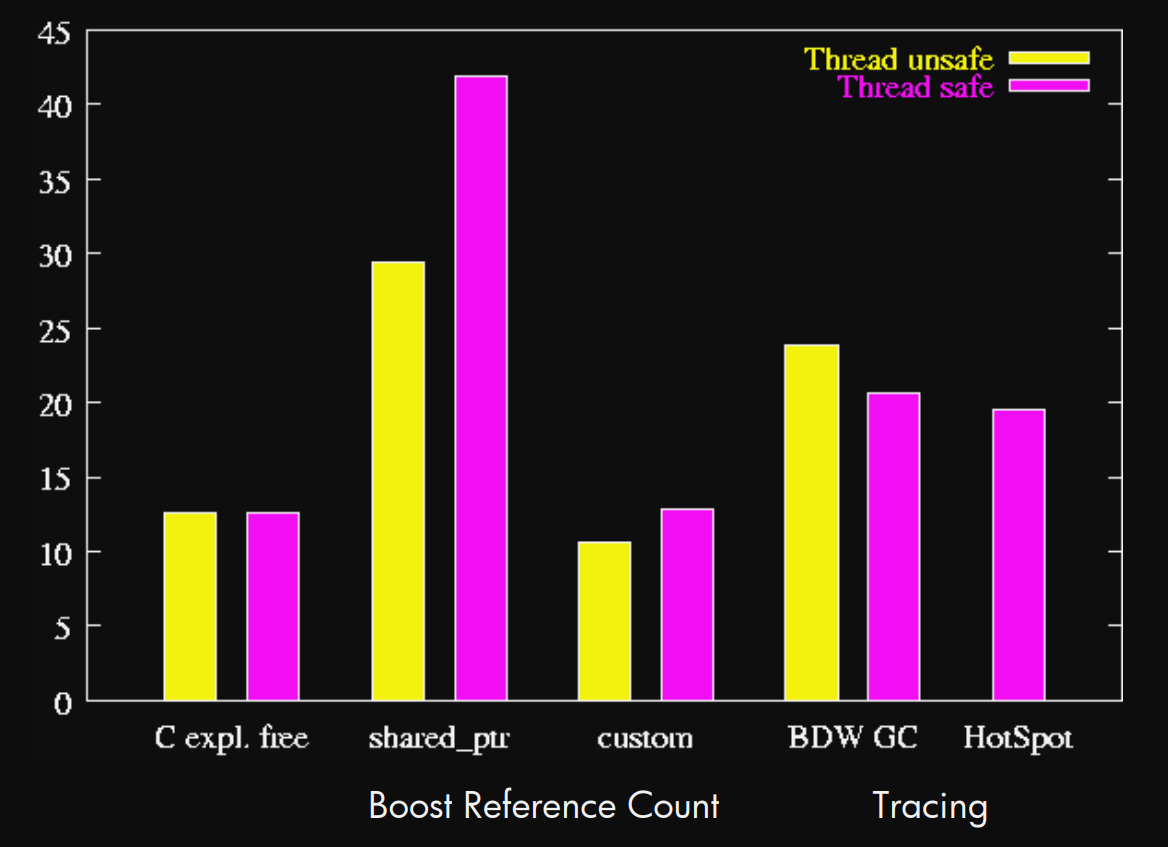
Max. space usage (MB) vs. others
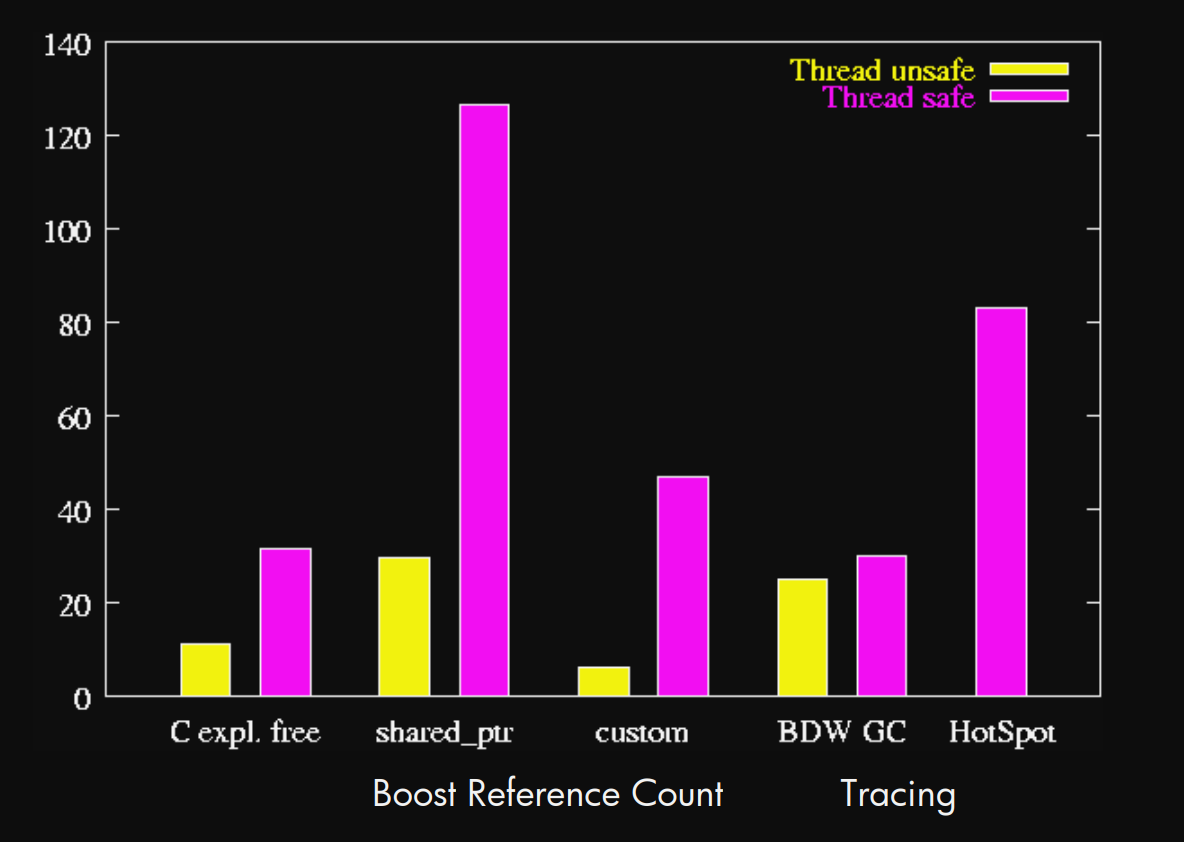
Max pause time (msecs) vs. others
But:
- GCBench uses small objects.
- Allocation + GC cost is proportional to object size.
- Redo experiment with 128 extra null pointer per node.
但是
GCBench使用小对象。- 分配 +
GC成本与对象大小成正比。 - 重做实验,每个节点有 128 个额外的空指针。
Large objects(msecs, MB, 2GHz Xeon)
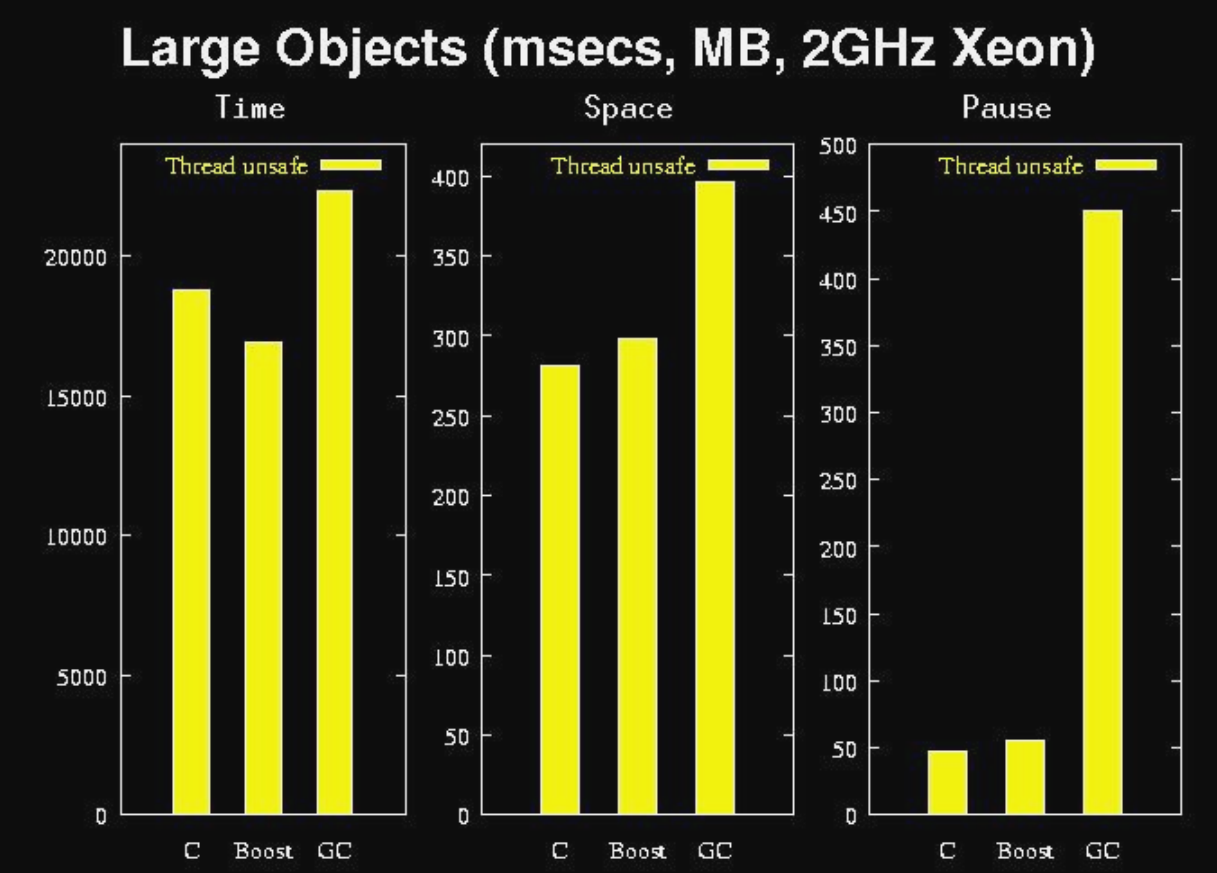
Large objects(thread-safe)
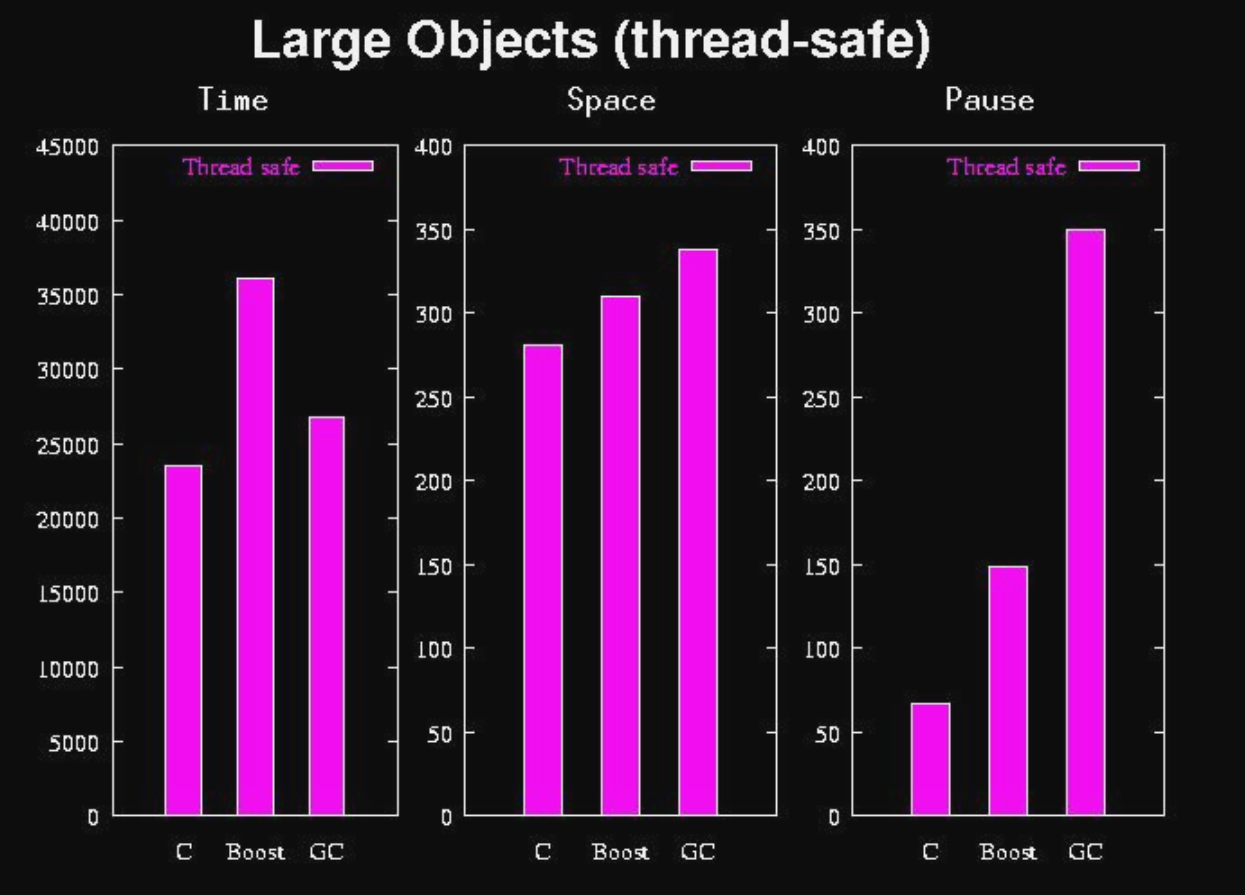
Some older measurements on malloc benchmarks
- These are a bit obsolete, things have probably improved, but ...
- Measured on 4xPPro (which was obsolete then).
malloc基准上的一些旧测量
- 这些有点过时了,情况可能有所改善,但是...
- 在
4xPPro(当时已经过时)上测量。
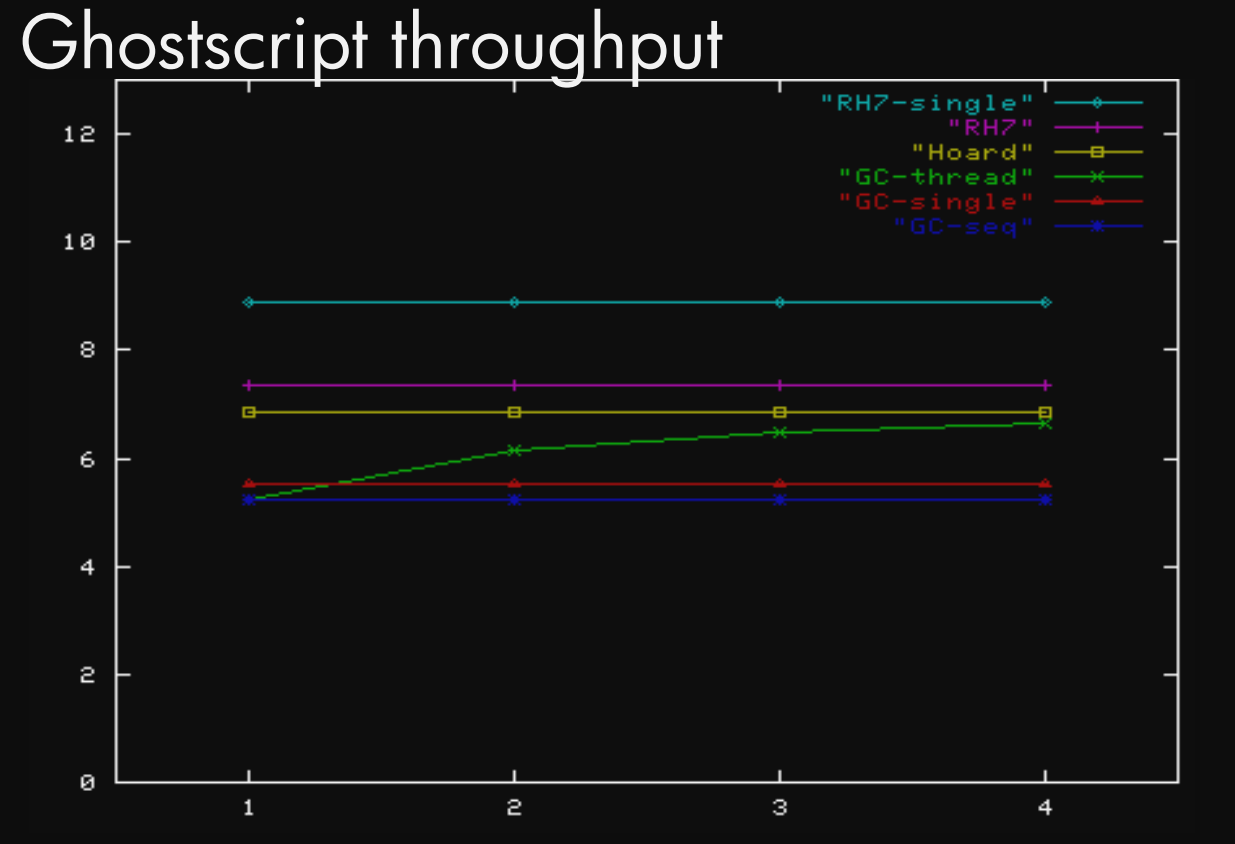
Ghostscript throughput
MT_GCBench2 throughput
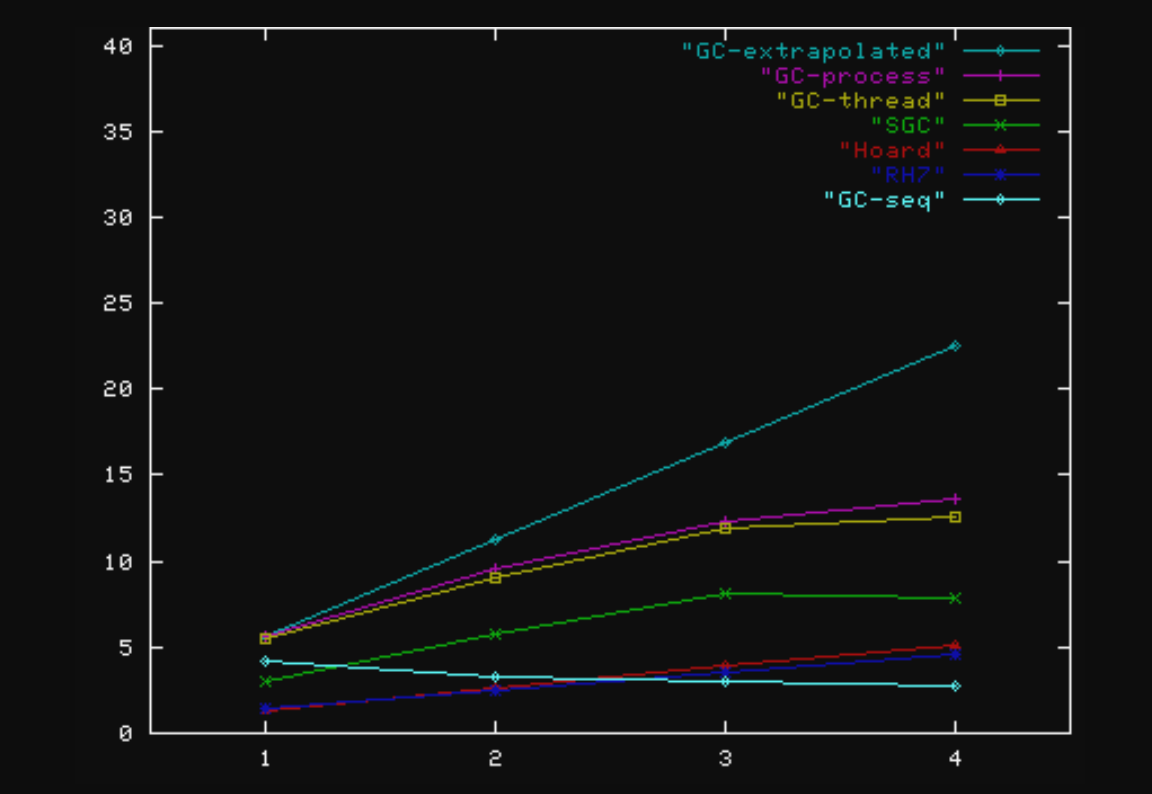
Larson (slightly mod.) benchmark throughput
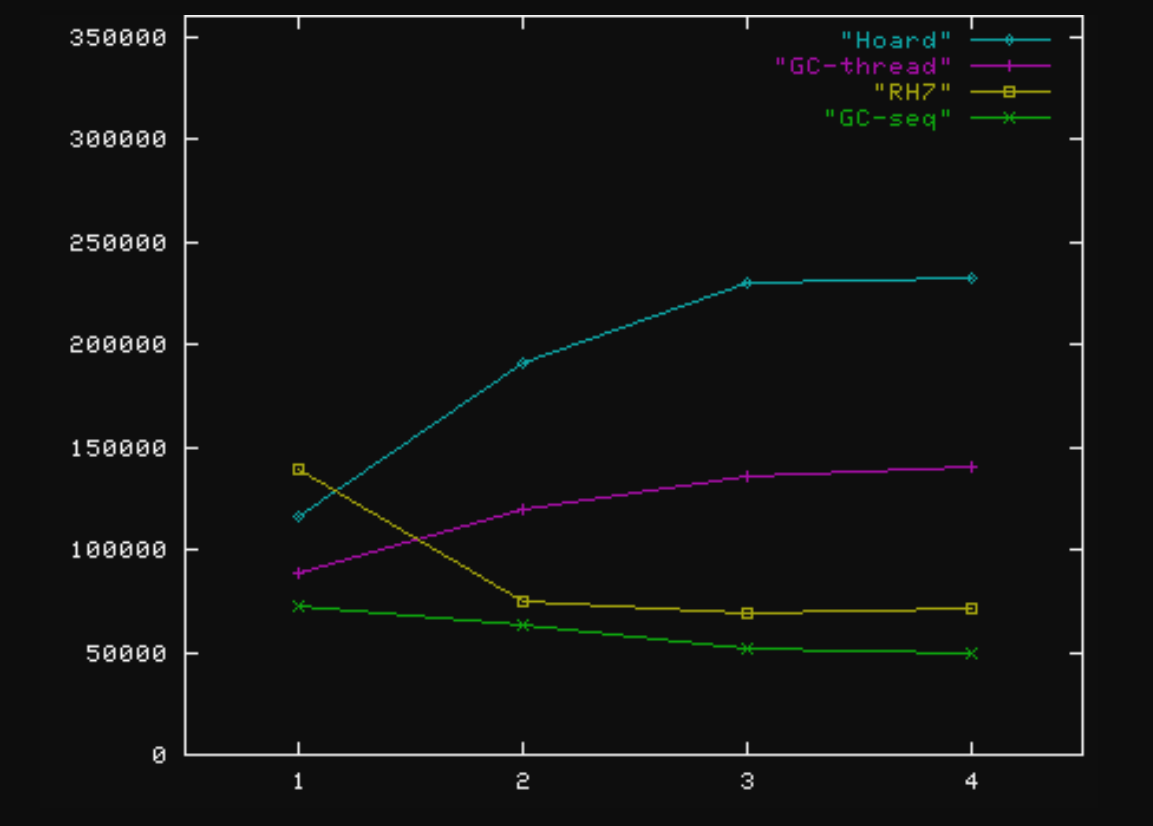
Larson-small throughput
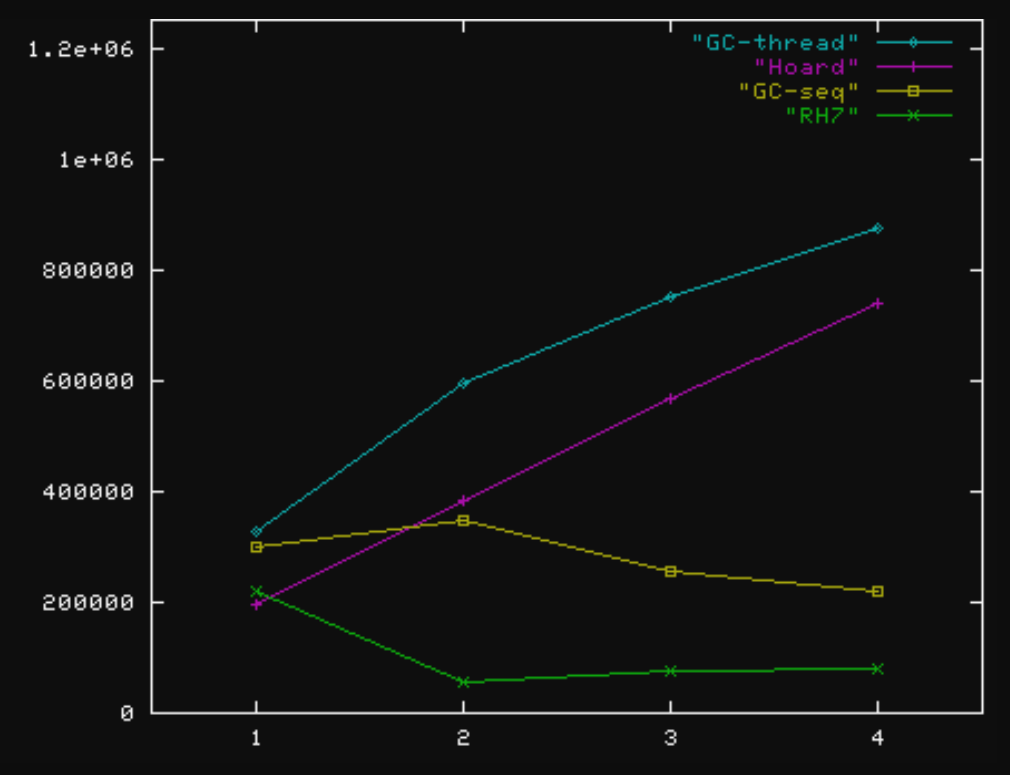
Other experiences
- Generally works quite well for small (< 100MB live data)
clients or on 64-bit machines.
- Sometimes needs a bit pointer location information for frequently occurring heap objects. Usually GC_MALLOC_ATOMIC is sufficient for C code.
- Some successful uses with much larger heaps.
- Some problems with 500MB heaps on 32-bit machines.
- Large arrays (> about 1MB) sometimes problematic.
- Fragmentation cost (for heaps > a few MB) is typically less than a factor of
2.
- Fragmentation essentially never an issue for small objects.
- Whole block coalescing is important.
- I haven't seen much of a problem with long running apps. (Vesta, Xerox printers).
- Stationary objects allow one word object headers in gcj.
其他经验
- 通常适用于小型(<
100MB实时数据)客户端或 64 位机器。- 有时需要频繁出现的堆对象的位指针位置信息。通常
GC_MALLOC_ATOMIC对于 C 代码就足够了。
- 有时需要频繁出现的堆对象的位指针位置信息。通常
- 一些成功的使用更大的堆。
- 32 位机器上
500MB堆的一些问题。 - 大型数组(> 大约
1MB)有时会出现问题。 - 碎片成本(对于 > 几
MB的堆)通常小于 2 倍。- 对于小物体来说,碎片化基本上不是问题。
- 整个块合并很重要。
- 我没有看到长时间运行的应用程序有什么问题。(
Vesta,Xerox printers)。 - 固定对象允许在
gcj中使用一个单词对象标题。
Space overhead of conservative GC
- Clever empirical study:
- Hirzel, Diwan, Henkel, "On the Usefulness of Type and Liveness Accuracy for
Garbage Collection", TOPLAS 24, 6, November 2002.
- Liveness information is usually more important than type information, especially on 64-bit platforms.
- Up to 62% space overhead.
- Hirzel, Diwan, Henkel, "On the Usefulness of Type and Liveness Accuracy for
Garbage Collection", TOPLAS 24, 6, November 2002.
- More theoretical study:
- Boehm, "Bounding Space Usage of Conservative Garbage Collectors", POPL 2002.
保守GC的空间开销
- 巧妙的实证研究:
Hirzel,Diwan,Henkel,“关于垃圾收集的类型和活性准确性的有用性”,TOPLAS 24, 6, November 2002。- 活性信息通常比类型信息更重要,尤其是在 64 位平台上。
- 高达 62% 的空间开销。
- 更多理论研究:
Boehm,“保守垃圾收集器的边界空间使用”,POPL 2002。
Conclusions
- Collector is still a useful tool for
- Avoiding manual memory management issues in C/C++.
- Quickly building language runtimes, especially, but not only, for research systems.
- Some GC research. (One underlying algorithm, mult. languages.)
- Performance is competitive with malloc/free.
- Usually wins for threads + small objects.
- Tracing performance is very close to best commercial JVMs.
- See also Smith and Morrisett, ISMM 98.
- Currently does less well when there is a large benefit from generational GC. (But see OOPSLA 2003 paper by Barabash et al.)
- There may be a cache cost to free list allocation.
- See work by Blackburn, Cheng, and McKinley.
- But I don't think we fully understand this yet...
结论
- 收集器仍然是一个有用的工具
- 避免
C/C++中的手动内存管理问题。 - 快速构建语言运行时,尤其是但不仅限于研究系统。
- 一些
GC研究。(一种底层算法,多种语言。)
- 避免
- 性能与
malloc/free具有竞争力。- 通常赢得线程+小对象。
- 跟踪性能非常接近最好的商业
JVM。- 另见
Smith和Morrisett,ISMM 98。 - 当分代
GC有很大的好处时,目前做得不太好。(但请参阅Barabash等人的OOPSLA 2003论文。)
- 另见
- 空闲列表分配可能会产生缓存成本。
- 参见
Blackburn、Cheng和McKinley的作品。 - 但我认为我们还没有完全理解这一点......
- 参见